SQL_自整理笔记
此文档给出考试和工程上常用的规则。 工程上要用到什么要约束什么,还是问 ai 查文档。
SQL 语法和关键字 大小写不区分
每条 SQL 语句都以 ; 结尾
语法描述上的一些符号约定 ↓
[]:表示"可有可无"
<>: 表示名称的含义
名称在 SQL 中是必须大小写区分的
模式和表
定义模式
create schema [ <模式名> ] authorization <用户名>
-- 为用户 Zhang 创建一个模式 Test,并且在其中定义一个表 Tab1
create schema Test authorization Zhang
create table Tab1(
Col1 smallint,
Col2 int,
Col3 char(20),
Col4 numeric(10, 3),
Col5 decimal(5, 2)
);
删除模式
drop schema <模式名> <cascade|restrict>
选取的两者必选其一 cascade(级联) —— 表示在删除模式的同时把该模式中所有的数据库对象全部删除; restrict(限制) —— 表示如果该模式中已经定义了数据库对象(如表、视图等),则拒绝删除语句的执行;
定义表
create table <表名>(
<列名> <数据类型> [列级完整性约束],
<列名> <数据类型> [列级完整性约束],
...
[<表级完整性约束>]
);
| 数据类型 | 描述 |
| char(n), character(n) | 字符/字符串。固定长度 n。 |
| varchar(n), character varying(n) | 字符/字符串。可变长度。最大长度 n。 |
| int(p), integer(p) | 整数值(没有小数点)。精度 p。 |
| smallint | 整数值(没有小数点)。精度 5。 |
| int, integer | 整数值(没有小数点)。精度 10。 |
| bigint | 整数值(没有小数点)。精度 19。 |
| decimal(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| numeric(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| float(p) | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| real | 近似数值,尾数精度 7。 |
| float | 近似数值,尾数精度 16。 |
| double precision | 近似数值,尾数精度 16。 |
| date | 日期。存储年、月、日的值。 |
| time | 时间。存储小时、分、秒的值。 |
| timestamp | 时间戳类型。存储年、月、日、小时、分、秒的值。 |
| interval | 时间间隔类型。由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| array | 元素的固定长度的有序集合 |
| multiset | 元素的可变长度的无序集合 |
| xml | 存储 XML 数据 |
[列级完整性约束]
primary key, 列指定主键约束
unique,唯一约束
not null,非空约束,默认值 NULL
default <默认值>,默认约束
auto_increment,属性值自动增加。默认情况下初始值和增量都为 1
[表级级完整性约束]
primary key(<列名1>, <列名2>),多字段联合主键
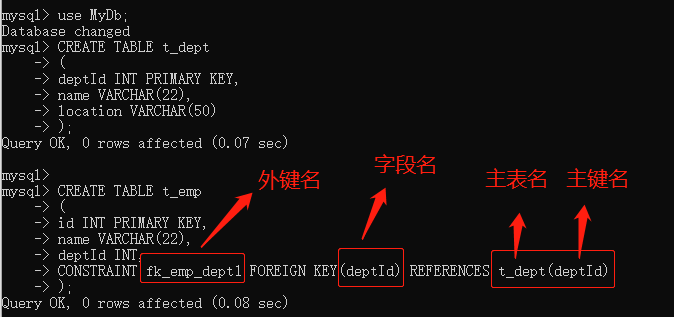
定义外键
-- 工程上写完整
[constraint <fk_子表_主表>] foreign key <子表字段> references <主表(主键)>
-- fk_子表名_主表名 在mysql中是默认命名规范
描述表
describe <表名>;
查看表的基本信息,包括:字段名、数据类型、是否有主键、是否有默认值等
下面的表是简单的描述:
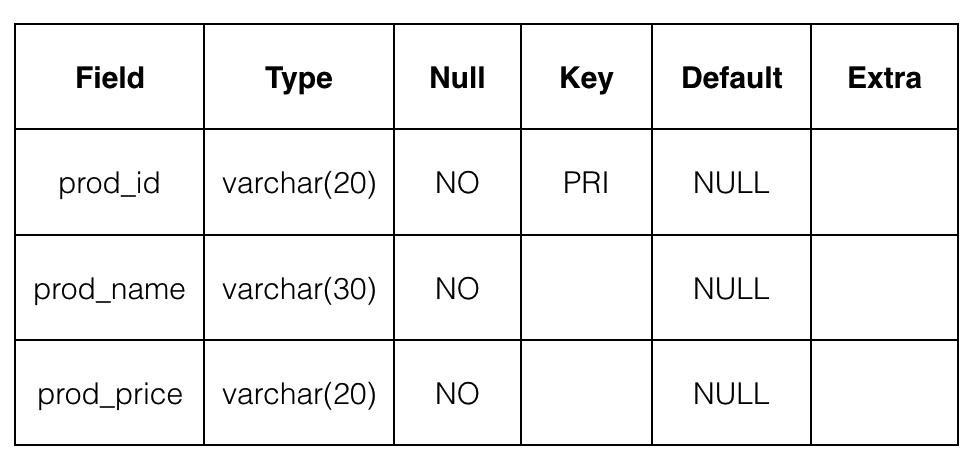
NULL: 表示该列是否能存储NULL值Key: 表示该列是否已编制索引,PRI表示该列是主键一部分Default: 表示该列是否有默认值,如果有的话值是多少Extra: 表示可以获取的与给定列有关的附加信息
show create table <表名>; 查看表的详细结构
删除表
drop table <表名> [restrict|cascade]
默认选项是 restrict,存在依赖该表的对象,此表不能被删除 选择 cascade,则删除该表没有限制条件。相关的依赖对象都可能被一起删除 *每个数据库产品,
drop策略有差别
对表中字段的增/删/改(修改表)
alter table <表名>
[add[column]]<新列名><数据类型>[完整性约束] -- 加列
[add<表级完整性约束>] -- 加约束
[drop[column]<列名>[cascade|restrict]] -- 删列
[rename column <列名> to <新列名>] -- 重命名列
[alter column <列名> type <数据类型>]; -- 该列类型
书例题 p76
索引
表的索引属于内模式范畴
create[unique][cluster] index <>
on <表名>(<列名>[<次序>][,<列名>[<次序>]]...);
-- unique 表明此索引的每一个索引值只对应唯一的数据记录
-- cluster 要建立的索引是聚集索引(就是加快查询速度)
-- 列名后的次序 可选 ASC(升序)/DESC(降序)
书例题 p79
表的查询
单表查询
-- 别名一般为缩写 ,内部引用,select中的别名可以作为结果
-- 完整写应该是[as <别名>],as只是个可读性标记,可以省略
select [all|distinct] <目标列表达式> [别名], ... /*相当于投影*/
/* all —— 不去重 distinct —— 去重*/
from <表名或视图名> [别名], ...
[where <条件表达式>] /*相当于选择*/
[group by <列名> [having <条件表达式>]] /*having作用于组,where作用于表*/
/*asc —— 升序 desc —— 降序*/
[order by <列名> [asc|desc]]
[limit <行数1> [offset <行数2>]]
| 查询条件 | 谓词 |
| 比较 | =, >, <, >=, <=, <>, !>, !<; not+上述比较运算符 |
| 确定范围 | between and, not between and |
| 确定集合 | in, not in <元组/子查询> |
| 字符匹配 | like, not like <含通配符的字符串(%任意长度,_任意单个字符)> |
| 空值 | is null, is not null |
| 多重条件(逻辑运算) | and, or, not |
| 聚集函数 | 作用 |
| count(*) | 统计元组个数 |
| count([distinct|all]<列名>) | 统计一列中值的个数 |
| sum([distinct|all]<列名>) | 计算一列值的总和(此列必须是数值列) |
| avg([distinct|all]<列名>) | 计算一列值的平均值(此列必须是数值列) |
| max([distinct|all]<列名>) | 求一列值中的最大值 |
| min([distinct|all]<列名>) | 求一列值中的最小值 |
where 子句不能用聚集函数作为条件表达式,要么就用子查询
group by 子句 常和 select 中用聚集函数绑定 ;若只是目标列,分组后只会查分组的第一行
连接查询
理论是关系代数的连接 (等值连接,非等值连接,自然连接,(左/右)外连接 * 见教材 p50)
from 多个表,where 子句里写条件(示例见教材 p92)
外连接特殊,语法是 [left|right] join <连接的表> on <条件表达式>
-- t_emp(id, name, deptId)
-- t_dept(deptId, name)
-- 查询:员工 + 部门名
SELECT e.id, e.name, d.name AS dept_name
FROM t_emp e
JOIN t_dept d -- 准备拼部门表,完整应该是INNER JOIN,缩写 JOIN,正常外连接,两边都不保留NULL值
ON e.deptId = d.deptId; -- 只有匹配的行才能拼上
-- 左外连接
-- 就算没有部门的员工也显示,非常常用
SELECT e.id, e.name, d.name AS dept_name
FROM t_emp e
LEFT JOIN t_dept d -- 完整 LEFT OUTER JOIN,缩写 LEFT JOIN
ON e.deptId = d.deptId;
嵌套查询
where 子查询(最常见)
-- 查“在技术部的员工”
SELECT *
FROM t_emp
WHERE deptId = (
SELECT deptId
FROM t_dept
WHERE name = '技术部'
);
from 子查询(当临时表用,最重要)
-- 给出每个部门人数 > 5 的部门
SELECT *
FROM (
SELECT deptId, COUNT(*) AS cnt
FROM t_emp
GROUP BY deptId
) t
WHERE t.cnt > 5;
查“存不存在”,where exists(子查询)
-- 查“有员工的部门”
SELECT *
FROM t_dept d
WHERE EXISTS (
SELECT 1
FROM t_emp e
WHERE e.deptId = d.deptId
);
“我需要一个中间结果再处理” → 子查询(FROM)
“我只关心有没有匹配” → EXISTS
“我要拼字段一起展示” → JOIN
“逻辑复杂但想分层写清楚” → 子查询
要注意的是子查询不要写出来性能开销太大,清晰且易维护
集合查询
对于多条 select 的结果集之间的集合运算(并/交/差)
SELECT name FROM t_emp WHERE deptId = 1
UNION ALL
SELECT name FROM t_emp WHERE deptId = 2;
-- 结果 = 集合A ∪ 集合B
-- union 先拼再distinct
-- union all 直接拼 (最常用)
--intersect 交集
--except / minus 差集
基于派生表的查询
把一条 select 的结果,当作一张临时表使用
SQL 没有“变量”,但你需要中间结果。派生表就是 SQL 的“中间变量”。用作结构分解
-- 先算 → 再查
SELECT *
FROM (
SELECT deptId, COUNT(*) AS cnt
FROM t_emp
GROUP BY deptId
) t
WHERE t.cnt > 5;
对数据(元组)的增/删/改(数据更新)
书例题 p108
插入数据
- 插入一个元组
insert into <表名>[(属性列 1[,<属性列 2>]...)] -- 对应常量
values (<常量 1>[,<常量 2>]...);
- 插入子查询结果
insert into <表名>[(<属性列 1>[,<属性列 2>...])]
子查询;
修改数据
update <表名>
set <列名>=<表达式>[,<列名>=<表达式>]...
[where<条件>];
删除数据
delete from <表名>
[where <条件>];
视图
书例题 p114
定义视图
- 建立视图
-- 将子查询的结果作为视图
create view <视图名>[(<列名>[,<列名>]...)]
as <子查询>
[with check option];
-- 该选项表示对视图进行 UPDATE、INSERT 和 DELETE 操作时
-- 要操作的元组满足视图定义中的谓词条件(即子查询中的条件表达式)
- 删除视图
drop view <视图名>[cascade];
cascade 级联表示把该视图和由它导出的所有视图一起删除
查询视图
DBMS 检查有效性,将视图查询转换成等价的对基本表的查询,然后再执行修正了的查询。这一转换过程称为视图消解(view resolution)。
具体看例题
更新视图
是指通过视图来插入、删除和修改数据,同样视图消解,最终是对基本表的更新操作。
视图的作用
- 视图能够对机密数据提供安全保护
- 视图对重构数据库提供了一定程度的逻辑独立性
- 视图能简化用户的操作
- 视图使用户能以多种角度看待同一个数据